
Redundant data means storing the same information more than once, i.e., redundant data could be removed without the loss of information. Redundancy can lead to anomalies. The different anomalies are insertion, deletion, and updation anomalies. In short
- Anomalies are the problems.
- This is the situation which is inconsistent of database.
Problems of Redundancy
Redundancy can cause problems during normal database operations. For example, when data are inserted into the database, the data must be duplicated wherever redundant versions of that data exist. Also when the data are updated, all redundant data must be simultaneously updated to reflect that change.
The three types of anomalies are explained below with an example table
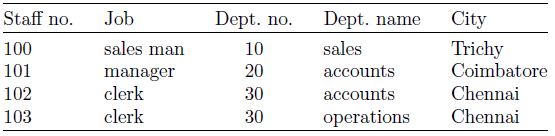
Insertion Anomaly
- We can't insert record because data is dependent on another data.
- We can't enter data because of absence of other data.
- For example, in the above table, We cannot insert a department without inserting a member of staff that works in that department .
Deletion Anomaly
- Deleting some wanted data will also delete some unwanted data.
- For example, in the above table,By removing, employee 100, we have removed all information pertaining to the sales department.
Update Anomaly
- We could change the name of the department that “100” works in without simultaneously changing the department that “102” works.
Normalization is the process of organizing the data in the database.
Normalization is used to minimize the redundancy from a relation or set of relation.
It is also used to eliminate the undesirable characteristics like insertion, update and delete anomalies.
Normalization divides the large table into the smaller table and links them using relationships.
The normal form is used to reduce redundancy from the database table.
0 comments :
Post a Comment
Note: only a member of this blog may post a comment.