
Logistic regression aims to solve classification problems. It does this by predicting categorical outcomes, unlike linear regression that predicts a continuous outcome.
Logistic regression is a statistical method used for binary classification tasks. It predicts the probability of an event occurring, such as whether an email is spam or not, or whether a customer will churn or not. Logistic regression is a powerful tool that can be used to model complex relationships between variables, and it is widely used in a variety of fields, including economics, finance, sociology, and psychology.
The formula for logistic regression is:
P(y = 1) = 1 / (1 + e^(-β0 + β1X1 + β2X2 + ... + βpX))
where:
- P(y = 1) is the probability that the event occurs
- β0 is the intercept
- β1, β2, ..., βp are the regression coefficients
- X1, X2, ..., Xp are the explanatory variables
In the simplest case there are two outcomes, which is called binomial, an example of which is predicting if a tumor is malignant or benign. Other cases have more than two outcomes to classify, in this case it is called multinomial. A common example for multinomial logistic regression would be predicting the class of an iris flower between 3 different species.
Here we will be using basic logistic regression to predict a binomial variable. This means it has only two possible outcomes.


What is Confusion Matrix and why you need it?
Well, it is a performance measurement for machine learning classification problem where output can be two or more classes. It is a table with 4 different combinations of predicted and actual values.

It is extremely useful for measuring Recall, Precision, Specificity, Accuracy, and most importantly AUC-ROC curves.
Let’s understand TP, FP, FN, TN in terms of pregnancy analogy.
True Positive:
Interpretation: You predicted positive and it’s true.
You predicted that a woman is pregnant and she actually is.
True Negative:
Interpretation: You predicted negative and it’s true.
You predicted that a man is not pregnant and he actually is not.
False Positive: (Type 1 Error)
Interpretation: You predicted positive and it’s false.
You predicted that a man is pregnant but he actually is not.
False Negative: (Type 2 Error)
Interpretation: You predicted negative and it’s false.
You predicted that a woman is not pregnant but she actually is.
Recall

The above equation can be explained by saying, from all the positive classes, how many we predicted correctly.
Recall should be high as possible.
Precision
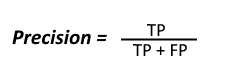
The above equation can be explained by saying, from all the classes we have predicted as positive, how many are actually positive.
Precision should be high as possible.
and
Accuracy
From all the classes (positive and negative), how many of them we have predicted correctly. In this case, it will be 4/7.
Accuracy should be high as possible.
F-measure

It is difficult to compare two models with low precision and high recall or vice versa. So to make them comparable, we use F-Score. F-score helps to measure Recall and Precision at the same time. It uses Harmonic Mean in place of Arithmetic Mean by punishing the extreme values more.
Now, we will find above for our Model



Applications of logistic regression:
- Predicting spam emails: Logistic regression can be used to predict whether an email is spam or not based on factors such as the sender, subject line, and content of the email.
- Modeling customer churn: Logistic regression can be used to model the likelihood of a customer churning, or canceling their service, based on factors such as their demographics, usage patterns, and satisfaction levels.
- Detecting fraudulent transactions: Logistic regression can be used to detect fraudulent transactions in real-time based on factors such as the transaction amount, location, and time of day.
Limitations of logistic regression:
-
Linearity: Logistic regression assumes that the relationship between the explanatory variables and the log odds of the event occurring is linear. If the relationship is nonlinear, logistic regression will not be accurate.
-
Multicollinearity: Multicollinearity occurs when two or more explanatory variables are highly correlated with each other. Multicollinearity can make it difficult to interpret the regression coefficients.
-
Overfitting: Overfitting occurs when the model fits the training data too closely and does not generalize well to new data. Overfitting can be reduced by using regularization techniques such as L1 or L2 regularization.
0 comments :
Post a Comment
Note: only a member of this blog may post a comment.