
Entropy:
To
Define Information Gain precisely, we begin by defining a measure which
is commonly used in information theory called Entropy. Entropy
basically tells us how impure a collection of data is. The term impure
here defines non-homogeneity. In other word we can say, “Entropy is the
measurement of homogeneity. It returns us the information about an
arbitrary dataset that how impure/non-homogeneous the data set is.”
Given
a collection of examples/dataset S, containing positive and negative
examples of some target concept, the entropy of S relative to this
boolean classification is-
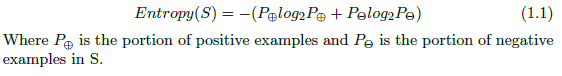
To illustrate this equation, we will do an example that calculates the entropy of our data set in Fig: 1. The dataset has 9 positive instances and 5 negative instances, therefore-

By observing closely on equations 1.2, 1.3 and 1.4; we can come to a conclusion that if the data set is completely homogeneous then the impurity is 0, therefore entropy is 0 (equation 1.4), but if the data set can be equally divided into two classes, then it is completely non-homogeneous & impurity is 100%, therefore entropy is 1 (equation 1.3).
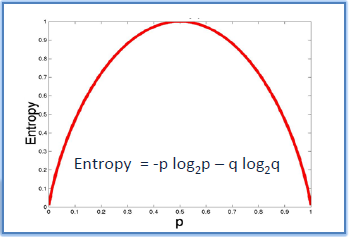
Now, if we try to plot the Entropy in a graph, it will look like Figure 2. It clearly shows that the Entropy is lowest when the data set is homogeneous and highest when the data set is completely non-homogeneous.

Information Gain:
Given Entropy is the measure of impurity in a collection of a dataset, now we can measure the effectiveness of an attribute in classifying the training set. The measure we will use called information gain, is simply the expected reduction in entropy caused by partitioning the data set according to this attribute. The information gain (Gain(S,A) of an attribute A relative to a collection of data set S, is defined as-
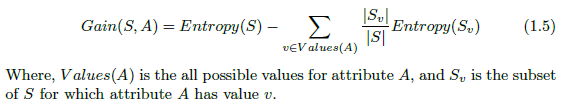
To become more clear, let’s use this equation and measure the information gain of attribute Wind from the dataset of Figure 1. The dataset has 14 instances, so the sample space is 14 where the sample has 9 positive and 5 negative instances. The Attribute Wind can have the values Weak or Strong. Therefore,
Values(Wind) = Weak, Strong

So, the information gain by the Wind attribute is 0.048. Let’s calculate the information gain by the Outlook attribute.

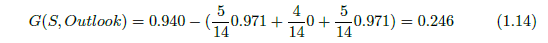
These two examples should make us clear that how we can calculate information gain. The information gain of the 4 attributes of Figure 1 dataset are:

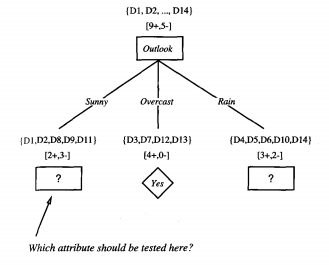
Remember, the main goal of measuring information gain is to find the attribute which is most useful to classify training set. Our ID3 algorithm will use the attribute as it’s root to build the decision tree. Then it will again calculate information gain to find the next node. As far as we calculated, the most useful attribute is “Outlook” as it is giving us more information than others. So, “Outlook” will be the root of our tree.
0 comments :
Post a Comment
Note: only a member of this blog may post a comment.